

O echipă de cercetători din cadrul Facultății de Matematică și Informatică a Universității Babeș-Bolyai a realizat un articol care face parte dintr-un proiect al cărui temă este identificarea şi recunoaşterea automată a emoţiilor în texte scrise în limba română.
Proiectul cuprinde două direcţii de cercetare: dezvoltarea şi îmbunătăţirea unor resurse în acest sens, precum şi implementarea unor tehnici bazate pe acestea în contextul unor aplicaţii precum analiza şi caracterizarea textelor literare sau studiul tulburărilor psihice în rândul utilizatorilor reţelelor de socializare.
Dezvoltarea RoEmoLex (Romanian Emotion Lexicon), un lexicon de cuvinte şi expresii în limba română a făcut parte din prima direcţie, încadrându-se într-un proces din mai mulţi paşi de adaptare din limba engleză, corectare, îmbunătăţire structurală şi îmbogăţire prin adăugarea unor termeni din resurse similare. Cuvintele și expresiile au fost categorizate pe baza a două etichete privitoare la valenţa termenului (Pozitivitate, Negativitate) şi opt etichete emoţionale binare: Anticipare (Anticipation), Bucurie (Joy), Dezgust (Disgust), Frică (Fear), Furie (Anger), Încredere (Trust), Tristeţe (Sadness), Surpriză (Surprise).
Astfel, în cea de-a treia versiune a resursei, denumită RoEmoLex v.3, există intrări de tipul celor prezentate în tabelul următor. Spre exemplu, cuvântul vacanţă are valenţe pozitive (P = 1) şi exprimă emoţiile Anticipare (Anticipation =1) şi Bucurie (Joy=1). În mod similar, nedreptate are valenţe negative, şi exprimă Furie, Dezgust şi Tristeţe.
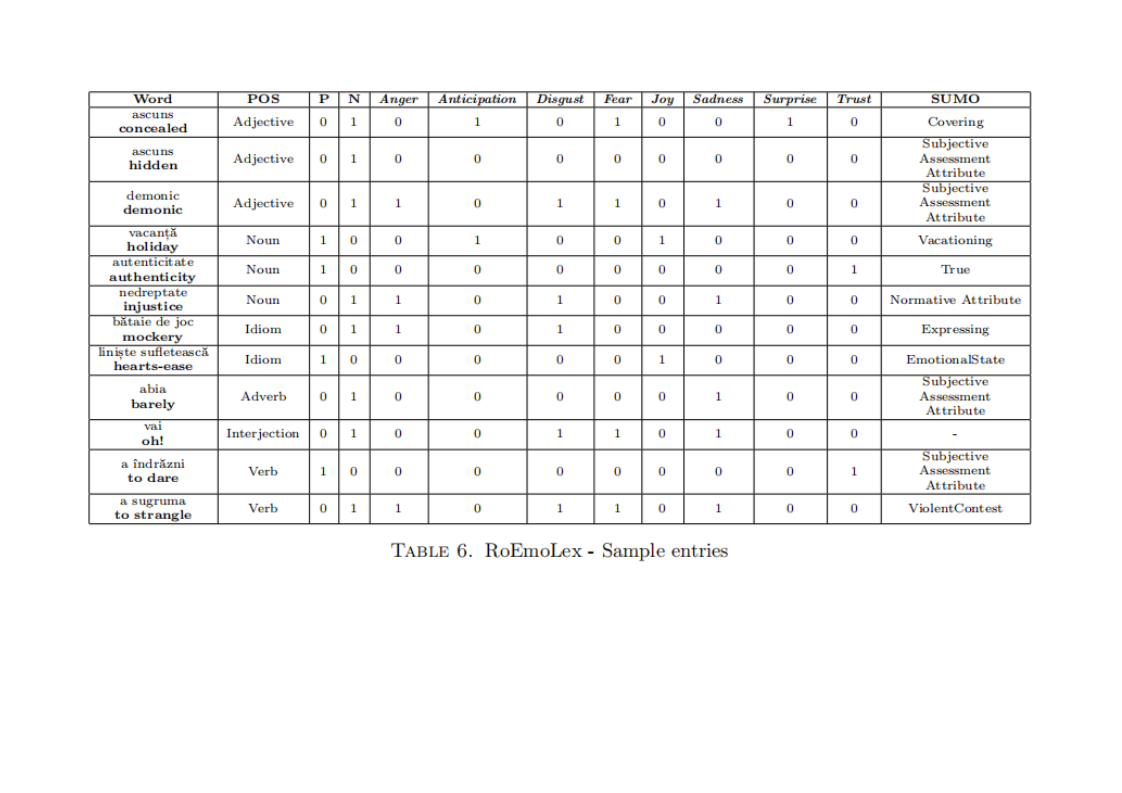
Aceste atribute pot fi utile în cazul unor task-uri de procesare de limbaj precum dezambiguizarea sensurilor cuvintelor într-un text şi determinarea ulterioară a conţinutului emoţional.
În RoEmoLex v.3, există 9177 astfel de intrări, împărţite după partea de vorbire pe care o reprezintă după cum urmează: substantive(47.92%), adjective(24.54%), verbe(16.57%), expresii (7.53%), adverbe (3.39%), interjecţii(0.05%). Substantivele şi adjectivele sunt cuvintele în care se întâlneşte cel mai frecvent un conţinut emoţional substanţial şi acestea sunt părţile de vorbire care se regăsesc cel mai des în categorii semnificative din punct de vedere emoţional (Stări emoționale, Atribute psihologice etc).
Astfel de categorii au constituit un punct de start într-o analiză a datelor din lexicon cu scopul de a descoperi dacă emoţiile exprimate de cuvinte sunt suficiente pentru a constitui grupări de cuvinte şi expresii cu aceeaşi semnificaţie (EmoSynsets).
Cu ajutorul FCA (Formal Concept Analysis), o tehnică de analiză a datelor bazată pe teoria conceptelor, a reieşit, spre exemplu, că în grupul cuvintelor din categoria Psychological Attributes, în mare parte, emoţiile exprimate împart termenii în seturi de sinonime (totale sau parţiale), fără a fi nevoie de alte atribute pentru separare. În figura de mai jos astfel de seturi sunt C2, C3 sau C5.
O altă statistică interesantă relevată de acest studiu este distribuţia emoţiilor în cadrul lexiconului: Frică (22.60%), Furie (20.66%), Tristeţe (19.79%), Încredere (19.02%), Dezgust (13.93%), Anticipare (12.48%), Bucurie (12.42%), Surpriză (8.24%).
În concluzie, ca urmare a analizei conţinutului lexiconului, RoEmoLex v.3 este propus ca o resursă utilă în aplicaţii de analiză a emoţiilor în texte în limba română, având un potențial aplicativ foarte larg.
Articolul a fost publicat în jurnalul academic Computer Speech & Language, iar pentru mai multe detalii referitoare la acest studiu vă invităm să accesați: https://www.sciencedirect.com/science/article/pii/S0885230818302092.

